The main stages of my academic writing process:
- Note-taking (empirical data collection or taking reading notes);
- Analysis and evaluation, resulting in
- an abstracted list of observations;
- a selection of evidence (quotes and notes);
- Organising these findings by: [2 and 3 can be done concurrently]
- Ordering the list into a hierarchical outline;
- Attaching selected evidence to list items;
- Developing a separate outline for a draft (journal article or thesis or book chapter):
- creating a hierarchical list of items (titles);
- attaching a selection of evidence (quotes and notes) to the items as inline notes;
- Writing the draft;
- Adding a reverse outline (headings and subheadings) to the draft [5 and 6 are a more or less simultaneous, recursive process] .
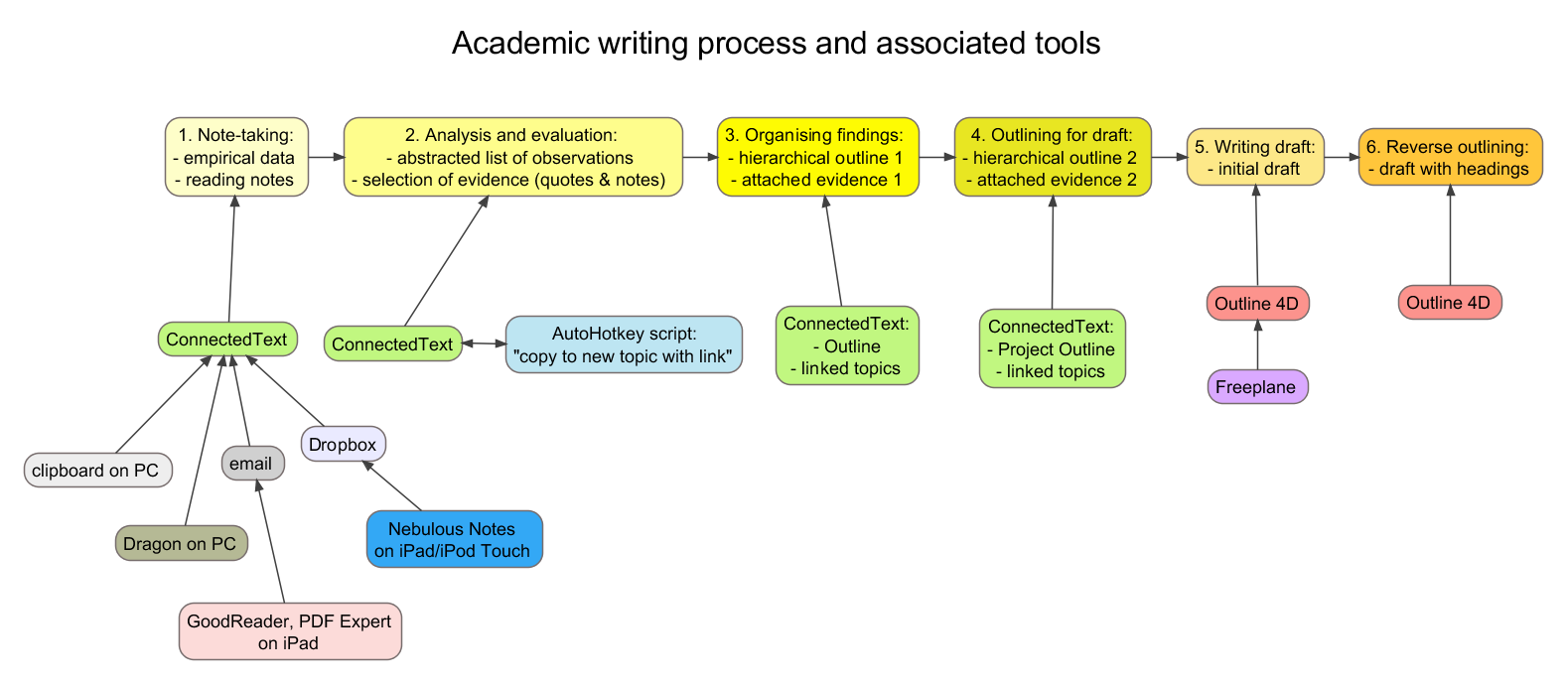
Tools needed:
- Note-taking (empirical data collection or taking reading notes);
- TOOLS:
- CT (ConnectedText) – Clipboard Catcher (or clipboard extender)
- Nebulous Notes on iPad/iPod Touch > Dropbox > CT
- Dragon NaturallySpeaking (on PC) > CT
- GoodReader, PDF Expert on iPad > email > CT
- Analysis and evaluation, resulting in
- an abstracted list of observations;
- a selection of evidence (quotes and notes);
- TOOLS:
- CT
- AutoHotkey script: “copy to new topic with links“
- Organising these findings by: [2 and 3 can be done concurrently]
- Ordering the list into a hierarchical outline;
- Attaching selected evidence to outline items;
- TOOLS:
- CT outline (occasionally exported to and imported back from Natara Bonsai)
- CT outline + linked CT topics
- Developing a separate outline for a draft (journal article or thesis or book chapter):
- creating a hierarchical list of items (titles);
- attaching a selection of evidence (quotes and notes) to the items as inline notes;
- TOOLS:
- CT Project Outline with links to topics
- Writing the draft;
- TOOLS:
- Outline 4D
- Freeplane
- Adding a reverse outline (headings and subheadings) to the draft.
- TOOLS:
Update (24/01/2013)
The above chart could have been more representative by having an arrow between ConnectedText in Step 4 and Freeplane in Step 5, as the CT project outline would be exported as a .mm file and imported into Freeplane. This is an important relationship as the links to the selected CT topics will be preserved and remain clickable, thus turning CT+Freeplane into a virtual dual-pane outliner/notes organiser.
Also, Steps 5 and 6 should have been alongside each other or at least there should have been arrows pointing back from 6 to 5, as the reverse outlining process is part of the drafting process. After writing 3 or 4 paragraphs I immediately add headings and sub-headings and slot them into Outline 4D’s single-pane hierarchical outline.
Update 2 (24/01/2013)
Here is an amended chart, taking into consideration the above corrections:
 Update 3 (24/01/2013)
Update 3 (24/01/2013)
Upon further reflection this is still not an entirely accurate picture of the entire process and set-up. An additional element emerges in Stages 5 and 6: the management of writing fragments that have to be removed from the draft in Outline 4D during interim editing and need to be kept apart. I may reuse some of these later, if and when the need arises.
Initially I just used a text document in NoteTab for this. But as the number of fragments grew, I needed a more sophisticated solution with the ability to split text into paragraphs and rearrange them in a hierarchical outline. For now I’ve been using Scrivener for Windows for this, which works well as a two-pane organiser of notes and also has the handy “split selection with title” command for breaking up a text into segments. However, I find Scrivener a bit of an overkill (and too slow on my Windows 7 system) for this. I’d prefer to use a lightweight, small footprint two-pane outliner that allows for the easy rearrangement of fragments.


